
Actuarial AI is advancing faster than most carriers' pricing infrastructure can keep up - and the carriers falling behind are mispricing risk as a result.
Peggy Brinkman, a principal actuary at Milliman, maps the trajectory: from univariate actuarial techniques, through generalized linear models, to gradient boosted machine models, and now to explainable boosting machines - a class of model that delivers gradient boosting accuracy with the interpretability that state regulators require for rate filing approval. The shift is happening across the industry, but at very different speeds. "New modeling techniques can extract more value from the same data in terms of risk understanding," Brinkman said. "Advances in methodologies are as important as bringing in new data sources."
Every step forward in modeling methodology runs on expanded computing power. The chart below shows how dramatically that capacity has grown - and why the trajectory matters for carriers investing in risk analytics today.
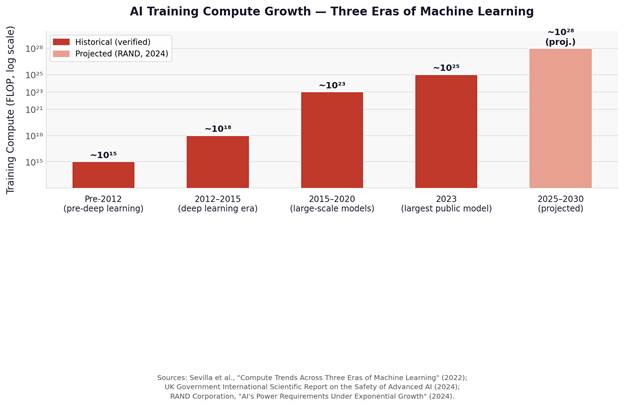
Sources: Sevilla et al., "Compute Trends Across Three Eras of Machine Learning" (2022); UK Government International Scientific Report on the Safety of Advanced AI (2024); RAND Corporation, "AI's Power Requirements Under Exponential Growth" (2024).
From approximately 1×10¹⁵ floating point operations used to train notable machine learning models in 2010, compute has increased by a factor of ten billion by 2023, according to the UK government's international scientific report on advanced AI. Since 2012, the amount of compute used to train leading models has roughly doubled every six months - a rate that significantly outpaces Moore's Law. RAND projects fourfold annual growth in frontier training compute through 2030.
"Computing power and tools' ability to take advantage of it remain the primary constraints on how much data can be processed," Brinkman said. "The industry pushes those boundaries with new technologies." Cloud and distributed computing environments have extended what is tractable - calculations that took weeks now run in hours - and carriers with more capable cloud architectures can process more granular data, run more complex models, and update pricing more frequently.
Generalized linear models have anchored actuarial pricing for decades. They are transparent, auditable, and explainable to state insurance regulators - qualities that matter when pricing models must be filed and approved. Their constraint is expressiveness: they struggle to capture complex interactions between risk factors that do not fit linear assumptions.
Gradient boosted machines address that constraint. They construct pricing models from ensembles of decision trees, each correcting the errors of the last, producing substantially more accurate risk segmentation - particularly for perils like wildfire where vegetation, slope, wind, and structural characteristics interact in highly non-linear ways. The regulatory barrier has been explainability: gradient boosted machines are notoriously opaque, and regulators have been reluctant to approve models they cannot interpret.
Explainable boosting machines resolve that tension. "Carriers can now pursue the modeling accuracy that competitive differentiation requires without sacrificing the transparency that regulatory compliance demands," Brinkman said. EBMs are appearing in rate filings with growing frequency, and their adoption marks a structural shift in what is actuarially possible within a regulated pricing environment.
Satellite and aerial imagery are the most significant additions to carrier data stacks over the past five years. They enable automated assessment of property characteristics - roof condition, vegetation proximity, construction materials - at a scale and frequency that on-the-ground inspection cannot match. Credit data remains among the most predictive variables in auto insurance pricing. Telematics, now more than a decade into mainstream adoption, continues to improve as programs mature.
Internet of Things devices - sensors monitoring electrical systems, water leak detection, structural stress - represent the next generation of property risk data. Brinkman is direct about where that technology stands: "These applications are in a low-sample-size phase, not yet available at the scale required to build statistically credible pricing factors." The pattern is familiar - satellite imagery moved through the same transition over several years. IoT data is expected to follow the same path.
Technology investment in pricing models produces returns only when improved models can be filed and approved. Judson Boomhower of UC San Diego identifies regulatory approval burden as a meaningful constraint on adoption. "Real costs are involved in implementing sophisticated pricing systems," he said, "both from a backend technology and regulatory perspective."
Recent California reforms - making it easier to incorporate frontier catastrophe model outputs in rate cases and to include reinsurance costs in filings - represent a shift in that environment. Carriers navigating California's admitted market should review the California Department of Insurance's current guidance on catastrophe model use in rate filings. Whether those changes are sufficient to restore admitted market participation at scale remains to be tested. The modeling race is accelerating. The regulatory framework is catching up.





